Building a TIFF by Hand
14 Nov 2025 ∞
Recently a photographer asked me whether there was a better way to build very large TIFFs, a grid of tens of thousands of smaller images, in gigapixel range. My first thought was "sure", thinking I could use some CoreGraphics to put everything together without the overhead of displaying the images. However I quickly found that that perceived lack of overhead was not trivial, and attempting to render small (by comparison) images pushed would simply fail.
I spent a lot of time thinking it over, wondering if there was another angle to tackle the problem from. I wanted to turn this from an imaging problem to a data problem. Could I ignore the pixels and focus only on the bytes? Eventually I turned to the actual TIFF spec to learn how TIFFs are actually put together, and they are, in fact, quite elegant, composed of smaller sections of image data which are combined into the whole.
Usually those sections are made of up strips, a number of rows of the image, but that's not the only option: you can also use tiles. Quoting from Section 15 on tiled images:
However high-resolution images can be accessed more efficiently—and compression tends to work better—if the image is broken into roughly square tiles instead of horizontally-wide but vertically-narrow strips.
Building high-resolution files out of a grid of smaller components? Exactly the problem I was trying to solve.
Building a TIFF Builder
Naturally, to start building my very own TIFF I had to build a TIFF builder. The first thing a TIFF needs is a Image File Directory which describes an image. It contains entries for the size of the final image, compression (we'll get back to that), metadata, and where to final the pixel data in the file.
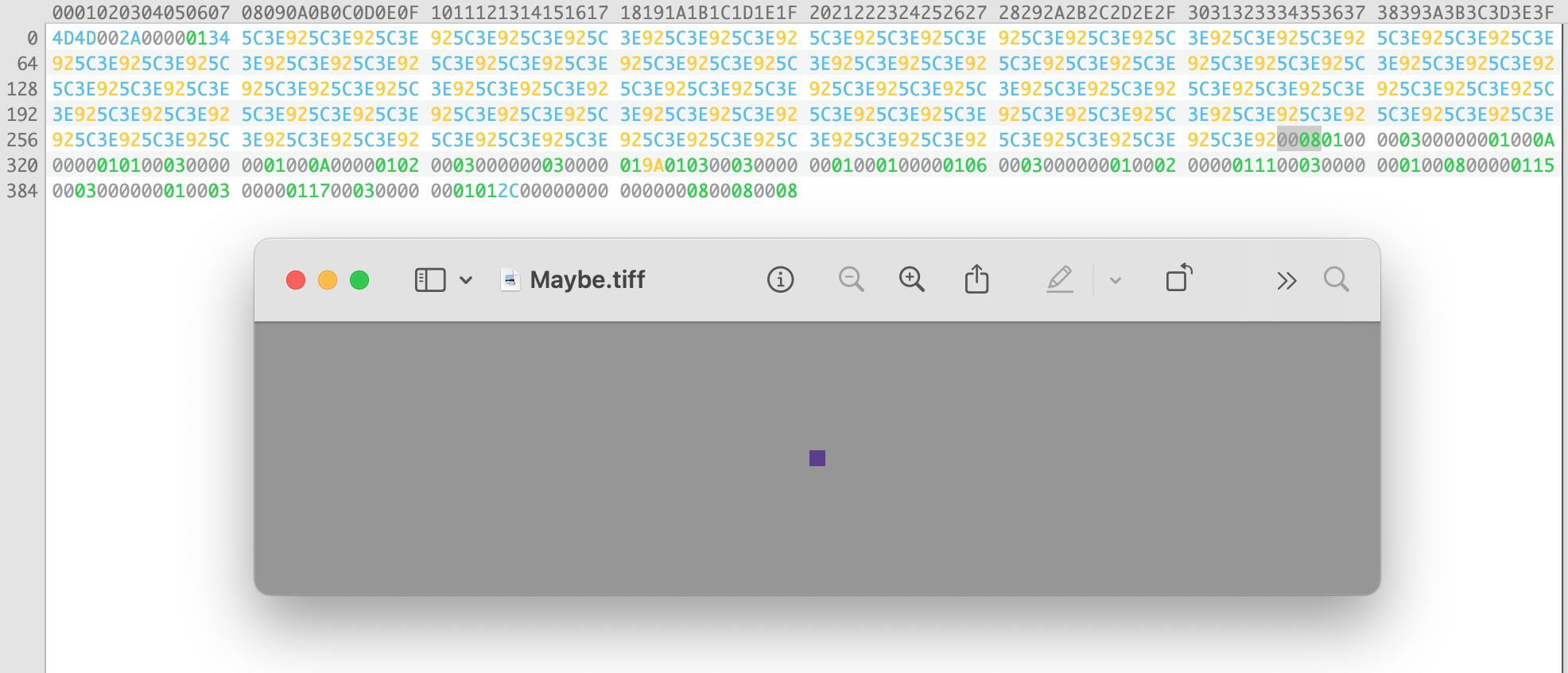
The very first TIFF I made that was readable was simply a small purple square. All of the values were specified directly in hex, the offsets manually calculated, with the most minimal scaffolding around to make an array of bytes.
After that I put a few more tags together and built a TIFF made of four tiles in my brand colors. With the basics in place I started writing more of the library, adding enums for tag types, and even added a new Result Builder to an existing library of mine for easily assembling ranges of bytes.
That's when I tried pushing the limits of how many tiles of random colors I could make. Offsets in TIFFs are stored in unsigned 32-bit integers, giving you an address space roughly of roughly four million bytes, which happens to be not that many bytes because I overflowed the UInt32 on the first test. I'd been using raw pixel data: one byte per channel. Remember how I mentioned we'd get back to compression?
Clever Algorithms
As the old saying goes "Hell is implementing clever algorithms." My first try at compression was to implement PackBits, it's relatively simple once you wrap your head around how it works, and I thought it would be perfect for my single-color tiles. What could possibly be more compressible than that?
PackBits made my tiles larger.
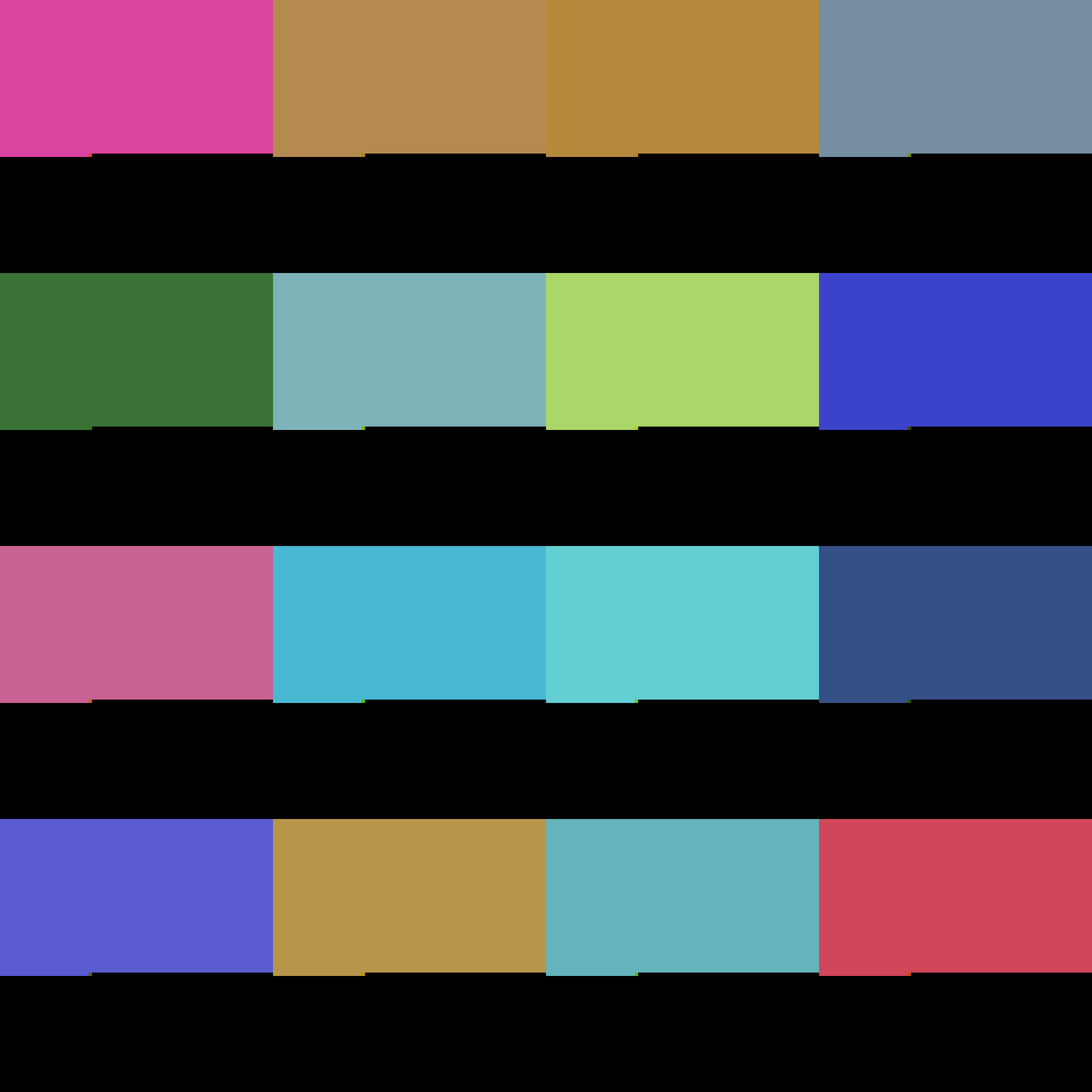
The algorithm is, to the specs credit, recommended for bi-lvel images, that is black and white. In this case it's a great way to compress data, just count the number of black or white bytes until you get to a different one. For my images each pixel is repeated, but the bytes never are. Oops, time to try another compression scheme.
LZW compression is the next simplest, which is to say it's not simple. It is, however, exceedingly clever. In broad strokes it encodes runs of bytes in a lookup table created on the fly, though I still don't understand how that table is recreated when decompressing, but that's not my problem. I managed to write a working1 implementation based on the pseudo-code example in the TIFF spec, and was able to encode readable TIFFs, relatively quickly. The issue then was what was being read.
My test images are simply squares of single random colors. See if you can spot the problem, it's subtle.
I was baffled as to why the compression worked until it just stopped. I shuffled the code around, looked at the sample, rewrote the code. Rinse and repeat. After a while I began to notice a pattern: small enough images had all their pixels, but larger images didn't, and interestingly no matter the size of the tiles they cut off after the same number of pixels2.
That's when I began to suspect the code size. LZW uses variable-length code words, starting at 9-bits, so as not to use too many bits in the final data. My implementation was throwing away data when it switched to 10-bit words.
After more refactoring I eventually found the very simple answer: I wasn't adding new entries to the table at the correct offset. A single addition operation and everything worked.
Glitches
In the process of generating TIFFs most of the failures weren't readable, but in the cases where the tags were correct and the pixels valid-ish they would open, and like the example above, be weird. I collected some of my favorites into a gallery, but here are a few examples.




The Library
I've been polishing off the library I wrote to write TIFFs. It's primarily going to be a data-driven way to build TIFFs, bring your own pre-sliced pixel data, with a focus on being as low overhead as possible. Once compression was in-place I was able to build gigapixel test images with 10-15 MBs of RAM usage and with proper multi-threading it can use as many cores as you can give at it.
I am trying to give it the best ergonomics I can, lots of strongly typed inits for fields, and hopefully as little manual offset management as possible. I'll publish it once it's in a place where I think other people can use it, even if I'm the only one who ever does. It's been fun exploring an entirely new domain and I have a feeling it's going to be a useful tool to have.